
The latest release of the Agents SDK ↗ makes it easier to run long work in the background, drive turns through one entry point, and keep chat agents working through deploys, evictions, and reconnects.
This release adds first-class detached (background) sub-agent runs with live progress and durable milestones, a single
runTurnturn-admission entry point, and a large round of recovery and reliability fixes that continue converging@cloudflare/thinkand@cloudflare/ai-chatonto one model.runAgentToolcan now dispatch a sub-agent without blocking the calling turn. A detached run returns a handle immediately and is owned by a durable, eviction-surviving backbone instead of being abandoned when the dispatching turn ends.JavaScript class OrdersAgent extends Think {async startImport(input) {// Fire-and-forget, or wire a durable completion callback// (by method name, like schedule()):await this.runAgentTool(ImportAgent, {input,detached: { onFinish: "onImportDone", maxBudgetMs: 60 * 60 * 1000 },});}// result.status: "completed" | "error" | "aborted" | "interrupted"async onImportDone(run, result) {}}TypeScript class OrdersAgent extends Think {async startImport(input) {// Fire-and-forget, or wire a durable completion callback// (by method name, like schedule()):await this.runAgentTool(ImportAgent, {input,detached: { onFinish: "onImportDone", maxBudgetMs: 60 * 60 * 1000 },});}// result.status: "completed" | "error" | "aborted" | "interrupted"async onImportDone(run, result) {}}Highlights:
- Durable, exactly-once-on-the-happy-path completion via a warm fast path plus a self-scheduling reconcile backbone that survives eviction and deploys.
- Bounded. An absolute
maxBudgetMsceiling (default 24h) andcancelAgentTool(runId)keep abandoned runs from holding a concurrency slot forever. detached: { notify: true }lets a finished background run inject a message back into the chat so the model reacts to the result — no hand-wiredonFinishneeded.
Sub-agents can also report mid-run progress that rides their own turn stream back to the parent's connected clients:
JavaScript // Inside the child sub-agent:await this.reportProgress({fraction: 0.6,phase: "deploying",message: "Generating menu page…",});TypeScript // Inside the child sub-agent:await this.reportProgress({fraction: 0.6,phase: "deploying",message: "Generating menu page…",});Progress surfaces on
AgentToolRunState.progressviauseAgentToolEvents, so a background-runs tray can render a live bar without drilling in, and the latest snapshot is persisted for inspection after eviction. Naming amilestonepromotes a signal to a durable, replayable row, anddetached: { onMilestones }can surface a milestone as a synthetic chat message ("narrate"for a cheap status line, or"react"to drive a model turn).@cloudflare/thinkadds a publicrunTurn(options)facade that unifies turn admission behind a singlemode:JavaScript await this.runTurn({ mode: "wait", messages }); // saveMessages / continueLastTurnawait this.runTurn({ mode: "submit", messages }); // durable submitMessagesawait this.runTurn({ mode: "stream", messages }); // chat()TypeScript await this.runTurn({ mode: "wait", messages }); // saveMessages / continueLastTurnawait this.runTurn({ mode: "submit", messages }); // durable submitMessagesawait this.runTurn({ mode: "stream", messages }); // chat()streammode accepts array and function inputs to matchwaitmode, and all entry points now route through a shared internal admission path that throws a clear error on nested blocking admissions that previously could deadlock.A large part of this release continues hardening recovery and converging
@cloudflare/thinkand@cloudflare/ai-chatonto one model:- Stream stall watchdog.
AIChatAgentcan detect and recover from a hung model/transport stream via the opt-inchatStreamStallTimeoutMswatchdog. WithchatRecoveryenabled the stall routes into the same bounded-recovery machinery a deploy or eviction uses; otherwise it surfaces as a terminal stream error so the spinner clears. - Interrupted tool-call repair.
AIChatAgentnow repairs a transcript with a dead server-tool call before re-entering inference (parity with@cloudflare/think), so a recovered turn no longer fails withAI_MissingToolResultsError. An overridablerepairInterruptedToolPart(part)hook lets apps customize the repaired shape. - Stuck status after reconnect. Fixed AI SDK
statusgetting stuck when a reconnect races a turn that has been accepted but has not started streaming yet, so the UI now renders the in-flight turn instead of settling onready. - Live "recovering…" on connect.
AIChatAgentnow replays the recovering status to a client that connects mid-recovery, souseAgentChat'sisRecoveringreflects in-progress recovery immediately instead of appearing frozen. - Terminal connection failures. The client stops reconnecting on terminal WebSocket close events and exposes them via
connectionError/onConnectionErroronAgentClient,useAgent, anduseAgentChat. - Agent-tool child recovery. A healthy long-running sub-agent run is no longer abandoned as
interruptedafter a deploy (both@cloudflare/thinkandAIChatAgent). - Workflows from sub-agent facets. Agent Workflows can now start from sub-agent facets, with callbacks and Workflow RPC routed back to the originating facet.
- Plus forward-progress crediting convergence, broadcast-first give-up ordering, an event-driven auto-continuation barrier, and structured row-size compaction in
AIChatAgent.
- Shared chat React core. A new
agents/chat/reactentry exposesuseAgentChat, transport helpers, and shared wire types, withsyncMessagesToServerfor server-authoritative transcript storage.@cloudflare/think/reactand@cloudflare/ai-chat/reactare now thin wrappers over it. - Optional
aipeer. The rootagentsand@cloudflare/codemoderuntimes no longer reference AI SDK types, so they bundle withoutai/zodinstalled; AI-specific entry points still require the peer when imported.just-bashlikewise moves to an optional peer used only by the skills bash runner. - Code Mode. The default
DynamicWorkerExecutortimeout increases from 30s to 60s, executions now dispose the dynamically-loaded Worker and its RPC stub after each run (fixing a flaky isolate-shutdown assertion), connector imports are cleaned up, and the outer MCP tool-call context is passed toopenApiMcpServerrequest callbacks. - Voice. Voice turns now support AI SDK
fullStreamresponses (and warn whentextStreamis used). - MCP.
McpAgentserver-to-client requests can now be sent from callbacks that do not inherit the agent's async context, including callbacks reached through Worker Loader RPC. - Experimental: server actions and channels. This release lays groundwork for guarded server actions (
action()/getActions()with a durable replay ledger and approvals) and a unified channels surface (configureChannels(),deliverNotice()). Both are experimental and their APIs may change, so we don't recommend depending on them yet.
To update to the latest version:
npm i agents@latest @cloudflare/think@latest @cloudflare/ai-chat@latest @cloudflare/codemode@latest @cloudflare/voice@latestyarn add agents@latest @cloudflare/think@latest @cloudflare/ai-chat@latest @cloudflare/codemode@latest @cloudflare/voice@latestpnpm add agents@latest @cloudflare/think@latest @cloudflare/ai-chat@latest @cloudflare/codemode@latest @cloudflare/voice@latestbun add agents@latest @cloudflare/think@latest @cloudflare/ai-chat@latest @cloudflare/codemode@latest @cloudflare/voice@latestRefer to the Think documentation, Code Mode documentation, and Agents documentation for more information.
AI Search now gives you more control over similarity cache freshness. Similarity cache helps reduce latency and inference cost by reusing responses for semantically similar queries.
With these updates, you can choose how long responses are eligible for reuse and clear cached responses when they may be stale.
Previously, AI Search cached responses for a fixed duration of 30 days. Cached responses now use the instance's
cache_ttlsetting, and the default is 48 hours.You can set
cache_ttlwhen creating or updating an instance to choose a cache duration from 10 minutes to 6 days.Use a shorter TTL when your source content changes frequently and freshness is more important. Use a longer TTL when your content is stable and you want more cache reuse.
For example, set
cache_ttlto518400to retain cached responses for 6 days:{"cache_ttl": 518400}You can also purge all cached responses for an instance on demand. Purging cached responses does not delete indexed content or source files.
It prevents AI Search from reusing previous cached responses, so subsequent similar queries generate fresh answers and repopulate the cache.
Terminal window curl -X POST "https://api.cloudflare.com/client/v4/accounts/$ACCOUNT_ID/ai-search/instances/$INSTANCE_NAME/purge_cache" \-H "Authorization: Bearer $CLOUDFLARE_API_TOKEN"You can also purge cached responses from the instance settings page in the Cloudflare dashboard.
Refer to similarity cache for the full list of supported
cache_ttlvalues and more details about cache behavior.
The latest release of the Agents SDK ↗ makes it easier to build agents that can safely interact with real systems and keep working through interruptions.
Agents can now browse websites through Browser Run, write code against external tools through Code Mode, use client-provided tools when delegating to Think sub-agents, and recover more reliably from deploys, Durable Object evictions, and connection churn.
Agents can now use Browser Run through a single durable
browser_executetool. Instead of choosing from a fixed list of actions, the model writes code against the Chrome DevTools Protocol (CDP) and can inspect pages, capture screenshots, read rendered content, debug frontend behavior, and interact with live browser sessions.JavaScript const browserTools = createBrowserTools({ctx: this.ctx,browser: this.env.BROWSER,loader: this.env.LOADER,session: { mode: "dynamic" },});TypeScript const browserTools = createBrowserTools({ctx: this.ctx,browser: this.env.BROWSER,loader: this.env.LOADER,session: { mode: "dynamic" },});Browser sessions can be one-time, reused, or promoted from one-time to persistent during a run. This is useful when an agent needs a human to log in, complete MFA, or approve a sensitive action. The run can pause, keep the same tabs and cookies, and resume after approval.
The browser tools also add Live View URLs, optional session recording, and quick actions such as
browser_markdown,browser_extract,browser_links, andbrowser_scrapefor one-shot browsing tasks.Code Mode now uses
createCodemodeRuntime, connectors, and a durable execution log. This lets you give a model onecodemodetool instead of a large prompt full of tool definitions. The model can discover the capabilities it needs, write code against typed globals, and reuse saved snippets.JavaScript const runtime = createCodemodeRuntime({ctx: this.ctx,executor: new DynamicWorkerExecutor({ loader: this.env.LOADER }),connectors: [new GithubConnector(this.ctx, this.env, connection)],});const result = streamText({model,messages,tools: { codemode: runtime.tool() },});TypeScript const runtime = createCodemodeRuntime({ctx: this.ctx,executor: new DynamicWorkerExecutor({ loader: this.env.LOADER }),connectors: [new GithubConnector(this.ctx, this.env, connection)],});const result = streamText({model,messages,tools: { codemode: runtime.tool() },});When the code reaches an approval-gated action, the runtime pauses execution and returns a pending approval. After approval, completed calls replay from the durable log, the approved action runs, and the same code continues. This makes it practical to build agents that create issues, update external systems, or perform other side effects without custom pause-and-resume logic for every tool.
Think sub-agents can now use client-defined tools over the RPC
chat()path. A parent agent can pass tool schemas withclientToolsand resolve tool calls throughonClientToolCall. This lets delegated agents use caller-provided capabilities without requiring a browser WebSocket.JavaScript await child.chat(message, callback, {signal,clientTools: [{name: "get_user_timezone",description: "Get the caller's timezone",parameters: { type: "object" },},],onClientToolCall: async ({ toolName, input }) => {return runClientTool(toolName, input);},});TypeScript await child.chat(message, callback, {signal,clientTools: [{name: "get_user_timezone",description: "Get the caller's timezone",parameters: { type: "object" },},],onClientToolCall: async ({ toolName, input }) => {return runClientTool(toolName, input);},});Think Workflows also improve
step.prompt(). A prompt step now runs a full agentic turn before returning structured output, so the agent can call tools before producing the typed result. This makes Workflow steps more useful for durable triage, research, and approval flows.The unified Think execute tool can also include
cdp.*browser capabilities alongsidestate.*andtools.*when Browser Run is bound.Voice clients can route assistant audio to a specific output device. Use
outputDeviceIdwithuseVoiceAgent, or callclient.setOutputDevice()from the framework-agnostic client.JavaScript const voice = useVoiceAgent({agent: "MyVoiceAgent",outputDeviceId: selectedSpeakerId,});TypeScript const voice = useVoiceAgent({agent: "MyVoiceAgent",outputDeviceId: selectedSpeakerId,});Browsers without speaker-selection support continue playing through the default output device and report a non-fatal
outputDeviceError.This release includes several fixes for production agents:
useAgentandAgentClienthandle WebSocket replacement more reliably during reconnects and configuration changes.- Chat stream replay is more reliable after reconnects, deploys, and provider errors.
- Fiber recovery continues across multi-pass scans and backs off when recovery hooks keep failing.
- Agent teardown continues even when the request that started teardown is canceled.
- Large session histories use byte-budgeted reads to reduce memory pressure during startup.
To update to the latest version:
npm i agents@latest @cloudflare/think@latest @cloudflare/codemode@latest @cloudflare/ai-chat@latest @cloudflare/voice@latestyarn add agents@latest @cloudflare/think@latest @cloudflare/codemode@latest @cloudflare/ai-chat@latest @cloudflare/voice@latestpnpm add agents@latest @cloudflare/think@latest @cloudflare/codemode@latest @cloudflare/ai-chat@latest @cloudflare/voice@latestbun add agents@latest @cloudflare/think@latest @cloudflare/codemode@latest @cloudflare/ai-chat@latest @cloudflare/voice@latestRefer to the Code Mode documentation, Browser tools documentation, Think tools documentation, and Voice documentation for more information.
We are excited to announce GLM-5.2 on Workers AI, Z.ai's flagship agentic coding model.
@cf/zai-org/glm-5.2is a text generation model built for agentic coding workflows. With function calling and reasoning support, it can handle long codebases, multi-step planning, and tool-augmented agents.Key features and use cases:
- Agentic coding: Designed for autonomous coding tasks, long-horizon planning, and complex software engineering workflows
- Large context window: GLM-5.2 supports up to a 1,048,576 token context window. Workers AI is launching the model with a 262,144 token context window and plans to increase this in the future
- Function calling: Build agents that invoke tools and APIs across multiple conversation turns
- Reasoning: Tackles complex problem-solving and step-by-step reasoning tasks
Use GLM-5.2 through the Workers AI binding (
env.AI.run()), the REST API at/runor/v1/chat/completions, or AI Gateway.Pricing is available on the model page or pricing page.
AI Gateway logs now capture the user agent of the client that made each request, making it easier to identify which SDK, library, or application sent the traffic flowing through your gateway. For example, you can tell apart requests coming from
openai-pythonversus a custom application or a Cloudflare Worker.The user agent appears alongside the other details in each log entry, and you can filter logs by user agent (equals, does not equal, or contains) in the dashboard.
For more information, refer to Logging.
@cf/moonshotai/kimi-k2.7-codeis now available on Workers AI. Kimi K2.7 Code is a code-optimized variant of the Kimi K2 family, built on a Mixture-of-Experts architecture with 1T total parameters and 32B active per token.K2.7 Code delivers meaningful gains over K2.6 on coding and agentic benchmarks:
- +21.8% on Kimi Code Bench v2
- +11.0% on Program Bench
- +31.5% on MLS Bench Lite
K2.7 Code uses 30% fewer reasoning tokens compared to K2.6, reducing overthinking and lowering inference cost for reasoning-heavy workloads.
- 262.1k token context window for retaining full conversation history, tool definitions, and codebases across long-running agent sessions
- Long-horizon coding with improved instruction following and higher end-to-end coding task success rates
- Vision inputs for processing images alongside text
- Thinking mode with configurable reasoning depth via
chat_template_kwargs.thinking - Multi-turn tool calling for building agents that invoke tools across multiple conversation turns
- Structured outputs with JSON schema support
If you are migrating from Kimi K2.6, note the following:
- K2.7 Code is optimized for coding tasks with improved benchmark performance and reasoning efficiency
- Cached input token pricing is $0.19 per M tokens (vs $0.16 for K2.6)
- API usage is identical — no parameter changes required
Use Kimi K2.7 Code through the Workers AI binding (
env.AI.run()), the REST API at/ai/run, or the OpenAI-compatible endpoint at/v1/chat/completions. You can also use AI Gateway with any of these endpoints.For more information, refer to the Kimi K2.7 Code model page and pricing.
Browser Run's
/snapshotendpoint now supports aformatsparameter that lets you return multiple page formats in a single API call. Previously,/snapshotreturned only HTML content and a screenshot. You can now also include Markdown and the accessibility tree in the same response.These formats are particularly useful for AI agent workflows:
- Markdown provides a token-efficient representation of page content that LLMs can process directly, without parsing HTML markup.
- The accessibility tree provides a structured representation of a page's elements, including roles, labels, and hierarchy, helping LLMs understand page structure and navigate its contents.
The following example returns a screenshot, Markdown, and the accessibility tree in one call:
Terminal window curl -X POST 'https://api.cloudflare.com/client/v4/accounts/<accountId>/browser-rendering/snapshot' \-H 'Authorization: Bearer <apiToken>' \-H 'Content-Type: application/json' \-d '{"url": "https://example.com/","formats": ["screenshot", "markdown", "accessibilityTree"]}'TypeScript import Cloudflare from "cloudflare";const client = new Cloudflare({apiToken: process.env["CLOUDFLARE_API_TOKEN"],});const snapshot = await client.browserRendering.snapshot.create({account_id: process.env["CLOUDFLARE_ACCOUNT_ID"],url: "https://example.com/",formats: ["screenshot", "markdown", "accessibilityTree"],});console.log(snapshot.markdown);console.log(snapshot.accessibilityTree);TypeScript interface Env {BROWSER: BrowserRun;}export default {async fetch(request, env): Promise<Response> {return await env.BROWSER.quickAction("snapshot", {url: "https://example.com/",formats: ["screenshot", "markdown", "accessibilityTree"],});},} satisfies ExportedHandler<Env>;You must request at least two formats. If you only need one, use the respective single-format endpoint such as
/screenshotor/markdown.Refer to the
/snapshotdocumentation for the full list of accepted values.
AI Search now supports namespace-level Wrangler commands, making it easier to manage namespaces from your terminal, scripts, and agent workflows.
The following commands are available:
Command Description wrangler ai-search namespace listList AI Search namespaces wrangler ai-search namespace createCreate a new AI Search namespace wrangler ai-search namespace getGet details for a namespace wrangler ai-search namespace updateUpdate a namespace description wrangler ai-search namespace deleteDelete an AI Search namespace Create a namespace for a new application or tenant directly from the CLI:
Terminal window wrangler ai-search namespace create docs-production --description "Production documentation search"List namespaces with pagination or filter by name or description:
Terminal window wrangler ai-search namespace list --search docs --page 1 --per-page 10Use
--jsonwithlist,create,get, andupdateto return structured output that automation and AI agents can parse directly.Instance-level commands also now support a
--namespaceflag, so you can interact with instances inside a specific namespace from the CLI:Terminal window wrangler ai-search list --namespace docs-productionFor full usage details, refer to the AI Search Wrangler commands documentation.
Today we are announcing the deprecation of several features from the Sandbox SDK. The SDK has grown and matured substantially since it first launched. As agent workflows have developed, we have shipped many new features and experiments so developers can easily integrate secure, isolated code execution into their workflows.
We want the SDK to continue providing a stable foundation for agentic workflows while we iterate quickly on the codebase. These deprecated features have either been superseded by newer capabilities or seen low adoption. They will remain in the codebase until July 9, 2026, after which they will no longer be present in future Sandbox SDK versions.
In April 2026, we released the new RPC transport and deprecated the WebSocket transport. This setting governs how the sandbox container talks to the Workers ecosystem. The RPC transport removes the limitations of both the HTTP and WebSocket transports. As of June 9, 2026, it is the recommended default. HTTP and WebSocket transports will no longer be present in Sandbox SDK versions released after July 9, 2026.
To migrate before July 9, 2026, update the
SANDBOX_TRANSPORTvariable torpcor set thetransportoption when callinggetSandbox(). For more information, refer to the transport configuration documentation.The desktop feature landed as a technical demonstration of what can be done with the Sandbox SDK — controlling a full browser environment from within a sandbox. With Cloudflare Browser Run now available, this feature saw very little use. We have removed it in
0.10.2.We recently released support for Cloudflare Tunnel in the Sandbox SDK. This provides a robust API for exposing services running in your sandbox to the public internet. It fixes issues many were facing with local development and deployment to
workers.devdomains. To migrate fromexposePort()to tunnels, refer to the tunnels API documentation and the expose services guide.By default, the
exec()method in the Sandbox SDK maintains a default session across all calls, so acdin one call is honored in the next. This convenience helped developers writingexecstatements by hand, but confused agents and caused hard-to-trace bugs. As of0.10.3, we have introduced theenableDefaultSessionflag on thegetSandbox()interface to turn this off. Default sessions as a concept — and the flag — will be removed in an upcoming release.We recommend setting
enableDefaultSession: falsetoday and using thesandbox.createSession()API when you need the previous behavior.We are also consolidating all APIs that buffer data to support streaming by default. This includes
readFile,writeFile, andexec. The stream equivalents will be removed.We are exploring moving non-core features like the code interpreter, terminal, and git APIs into helpers. These features will retain their existing APIs, so migration should be simple.
If you use any of these features, refer to the 2026 deprecation migration guide. We also provide an agent skill to help with the migration.
For any questions, ask in the Cloudflare Developers Discord ↗.
AI Gateway now supports spend limits — cost-based budgets that track cumulative dollar spend and block requests when the budget is exceeded. Unlike rate limiting, which caps the number of requests, spend limits track actual cost based on token usage and model pricing.
You can scope limits by model, provider, or custom metadata dimensions. For example, give each user a $200/day budget, cap total gateway spend at $10,000/day, or limit a specific model to $50/day per user. Each rule uses a configurable time window with fixed or sliding enforcement.
Spend limits work with both Unified Billing and BYOK requests for models with known pricing.
For more details, refer to the Spend limits documentation.
Pay-as-you-go customers can now view billable usage and create budget alerts directly from the product overview pages for Workers & Pages, D1, R2, Workers KV, Queues, Vectorize, Durable Objects, and Containers. A new sidebar widget shows current-period spend and the billing cycle date range, alongside a button to create a budget alert.
The widget pulls from the same data as the Billable Usage dashboard and aligns to your billing cycle (or the current day on Free plans), so the numbers match your invoice. Enterprise contract accounts are not yet supported.
Selecting Create budget alert opens the budget alert flow inline so you can set a dollar threshold in the same place you are reviewing usage. Budget alerts apply to your total account-level spend across all products, not just the product page you create them from.
For more information, refer to the Usage-based billing documentation.
Agents SDK v0.14.0: Agent Skills, messengers, scheduled tasks, Workflows, and hardened chat recovery
The latest release of the Agents SDK ↗ adds four new ways to build with
@cloudflare/think: on-demand Agent Skills, chat messengers (starting with Telegram), declarative scheduled tasks, and durable reasoning steps inside Workflows. This release also significantly hardens durable chat recovery, so turns reliably ride through deploys, evictions, and stalled model streams in production.Give an agent a catalog of on-demand instructions, resources, and scripts. A skill source adds a catalog to the system prompt, and the model activates a skill only when a task matches — so a large library of capabilities does not bloat every prompt.
JavaScript import { Think, skills } from "@cloudflare/think";import bundledSkills from "agents:skills";export class SkillsAgent extends Think {getSkills() {return [bundledSkills,skills.r2(this.env.SKILLS_BUCKET, { prefix: "skills/" }),];}}TypeScript import { Think, skills } from "@cloudflare/think";import bundledSkills from "agents:skills";export class SkillsAgent extends Think<Env> {getSkills() {return [bundledSkills,skills.r2(this.env.SKILLS_BUCKET, { prefix: "skills/" }),];}}The
agents:skillsimport bundles a local./skillsdirectory through the Agents Vite plugin (one directory per skill, each with aSKILL.md). Skills can also load from R2 or a manifest. When skills are available, Think exposesactivate_skill,read_skill_resource, and an optionalrun_skill_scripttool. Skill loading is resilient: a duplicate or failing source is skipped with a warning instead of breaking the agent.Agent Skills are experimental, and script execution in particular is early. The API may change in a future release. We would love your feedback — tell us what you are building and what is missing in the Agents repository ↗.
Connect a Think agent directly to a chat platform. Think owns the webhook route, conversation routing, durable reply fiber, and streamed delivery back to the provider. Telegram ships as the first provider.
JavaScript import { Think } from "@cloudflare/think";import {defineMessengers,ThinkMessengerStateAgent,} from "@cloudflare/think/messengers";import telegramMessenger from "@cloudflare/think/messengers/telegram";export { ThinkMessengerStateAgent };export class SupportAgent extends Think {getMessengers() {return defineMessengers({telegram: telegramMessenger({token: this.env.TELEGRAM_BOT_TOKEN,userName: "support_bot",secretToken: this.env.TELEGRAM_WEBHOOK_SECRET_TOKEN,}),});}}TypeScript import { Think } from "@cloudflare/think";import {defineMessengers,ThinkMessengerStateAgent,} from "@cloudflare/think/messengers";import telegramMessenger from "@cloudflare/think/messengers/telegram";export { ThinkMessengerStateAgent };export class SupportAgent extends Think<Env> {getMessengers() {return defineMessengers({telegram: telegramMessenger({token: this.env.TELEGRAM_BOT_TOKEN,userName: "support_bot",secretToken: this.env.TELEGRAM_WEBHOOK_SECRET_TOKEN,}),});}}Each Chat SDK thread maps to its own Think sub-agent by default, so group chats and direct messages do not share memory. Multiple bots, custom conversation routing, and custom providers are all supported.
Declare recurring, timezone-aware prompts and handlers with a typed domain-specific language (DSL). Think reconciles the declarations on startup and re-arms the next occurrence after each run, backed by durable idempotent submissions.
JavaScript import { Think, defineScheduledTasks } from "@cloudflare/think";export class DigestAgent extends Think {getScheduledTasks() {return defineScheduledTasks({weeklyCommitReport: {schedule: "every week on monday at 09:00",prompt:"Compile my GitHub commits for the last week and summarize them.",},workout: {schedule: "every day at 08:00 in Europe/London",prompt: "Start my workout.",},});}}TypeScript import { Think, defineScheduledTasks } from "@cloudflare/think";export class DigestAgent extends Think<Env> {getScheduledTasks() {return defineScheduledTasks({weeklyCommitReport: {schedule: "every week on monday at 09:00",prompt:"Compile my GitHub commits for the last week and summarize them.",},workout: {schedule: "every day at 08:00 in Europe/London",prompt: "Start my workout.",},});}}Run a model-driven reasoning step inside a Cloudflare Workflow with
ThinkWorkflowandstep.prompt(), with durable typed structured output, long waits, and approval gates.JavaScript import { z } from "zod";import { ThinkWorkflow } from "@cloudflare/think/workflows";const draftSchema = z.object({title: z.string(),summary: z.string(),labels: z.array(z.string()),});export class TriageWorkflow extends ThinkWorkflow {async run(event, step) {const draft = await step.prompt("triage-issue", {prompt: `Triage issue #${event.payload.issueNumber}`,output: draftSchema,timeout: "3 days",});await step.do("apply-labels", async () => {await this.agent.applyLabels(draft.labels);});}}TypeScript import { z } from "zod";import { ThinkWorkflow } from "@cloudflare/think/workflows";import type { ThinkWorkflowStep } from "@cloudflare/think/workflows";import type { AgentWorkflowEvent } from "agents/workflows";const draftSchema = z.object({title: z.string(),summary: z.string(),labels: z.array(z.string()),});export class TriageWorkflow extends ThinkWorkflow<TriageAgent, Params> {async run(event: AgentWorkflowEvent<Params>, step: ThinkWorkflowStep) {const draft = await step.prompt("triage-issue", {prompt: `Triage issue #${event.payload.issueNumber}`,output: draftSchema,timeout: "3 days",});await step.do("apply-labels", async () => {await this.agent.applyLabels(draft.labels);});}}Durable chat turns have always been designed to survive a mid-turn deploy or Durable Object eviction. This release is a major hardening pass on that machinery for production.
- Better recovery during deploys. Turns now ride through continuous deploys and evictions without losing completed work or re-running tools that already ran.
- A live "recovering…" signal.
useAgentChatexposes a newisRecoveringflag, so a recovering turn shows progress instead of looking frozen. Most UIs renderisStreaming || isRecoveringas "busy". - Stalled streams recover. Set
chatStreamStallTimeoutMsto route a hung provider stream into the same recovery path instead of leaving an infinite spinner. - Sub-agents re-attach. On parent recovery, an in-flight
agentTool()child is re-attached to its result rather than abandoned and re-run, so long-running children no longer lose work under deploys.
- Resumable streams — In-flight tool calls over Server-Sent Events (SSE) survive a dropped connection. Clients reconnect with
Last-Event-IDand replay anything they missed. - Readable server IDs —
addMcpServeraccepts an optionalid, so tools surface as readable keys (for exampletool_github_create_pull_request) instead of opaque connection IDs. - Better handling of concurrent requests — Overlapping JSON-RPC requests are now correctly correlated to their responses across the HTTP and RPC transports.
- Compaction — A
Session'stokenCounternow also drives the compaction boundary decision ("what to compress"), not just the fire/no-fire trigger. @cloudflare/worker-bundler— Adds avirtualModulesoption tocreateWorkerto provide in-memory module source during bundling.- Client-tool continuations — Parallel tool results now coalesce into a single continuation, immediate resume requests attach to the pending continuation, and server-side
needsApprovalcontinuations resume reliably after approval.
To update to the latest version:
npm i agents@latest @cloudflare/think@latest @cloudflare/ai-chat@latestyarn add agents@latest @cloudflare/think@latest @cloudflare/ai-chat@latestpnpm add agents@latest @cloudflare/think@latest @cloudflare/ai-chat@latestbun add agents@latest @cloudflare/think@latest @cloudflare/ai-chat@latestRefer to the Agents API reference and Chat agents documentation for more information.
Sandboxes can expose a service running inside the container on a public preview URL through the
sandbox.tunnelsnamespace. The SDK usescloudflaredinside the sandbox so you can share a running service without configuringexposePort()or a custom domain.By default,
sandbox.tunnels.get(port)creates a quick tunnel ↗ on a zero-config*.trycloudflare.comURL — no Cloudflare account, DNS record, or custom domain required. This is perfect for quick development and for.workers.devdeployments.JavaScript import { getSandbox } from "@cloudflare/sandbox";const sandbox = getSandbox(env.Sandbox, "my-sandbox");await sandbox.startProcess("python -m http.server 8080");const tunnel = await sandbox.tunnels.get(8080);console.log(tunnel.url); // → https://random-words-here.trycloudflare.comTypeScript import { getSandbox } from "@cloudflare/sandbox";const sandbox = getSandbox(env.Sandbox, "my-sandbox");await sandbox.startProcess("python -m http.server 8080");const tunnel = await sandbox.tunnels.get(8080);console.log(tunnel.url); // → https://random-words-here.trycloudflare.comFor more control you can create a named tunnel through
sandbox.tunnels.get(port, { name }). A named tunnel binds a hostname (<name>.<your-zone>) backed by a Cloudflare Tunnel and a CNAME record on your zone resulting in something like https://my-app-preview.example.com ↗.Unlike quick tunnels, which generate a new random URL each time, a named tunnel produces a persistent URL that survives container restarts. This makes named tunnels suitable for production use cases where you want control over the tunnel and it's origin.
JavaScript const tunnel = await sandbox.tunnels.get(8080, { name: "my-app-preview" });console.log(tunnel.url); // → https://my-app-preview.example.comTypeScript const tunnel = await sandbox.tunnels.get(8080, { name: "my-app-preview" });console.log(tunnel.url); // → https://my-app-preview.example.comCalling
sandbox.destroy()tears down the Cloudflare Tunnel and the associated DNS record alongside the container, so you do not leave dangling tunnels or records behind.To update to the latest version:
npm i @cloudflare/sandbox@latestyarn add @cloudflare/sandbox@latestpnpm add @cloudflare/sandbox@latestbun add @cloudflare/sandbox@latestFor full API details, refer to the Sandbox tunnels reference.
You can now call Browser Run Quick Actions directly from a Cloudflare Worker using the
quickAction()method on the browser binding. This simplifies how Workers interact with Browser Run by removing the need for API tokens or external HTTP requests. Your Worker communicates with Browser Run directly over Cloudflare's network, resulting in simpler code and lower latency.With the
quickAction()method you can:- Capture screenshots from URLs or HTML
- Generate PDFs with custom styling, headers, and footers
- Extract HTML content from fully rendered pages
- Convert pages to Markdown
- Extract structured JSON using AI
- Scrape elements with CSS selectors
- Get all links from a page
- Capture snapshots (HTML + screenshot in one request)
To get started, add a browser binding to your Wrangler configuration:
JSONC {"compatibility_date": "2026-03-24","browser": {"binding": "BROWSER"}}TOML compatibility_date = "2026-03-24"[browser]binding = "BROWSER"Then call any Quick Action directly from your Worker. For example, to capture a screenshot:
JavaScript const screenshot = await env.BROWSER.quickAction("screenshot", {url: "https://www.cloudflare.com/",});TypeScript const screenshot = await env.BROWSER.quickAction("screenshot", {url: "https://www.cloudflare.com/",});The
quickAction()method requires a compatibility date of2026-03-24or later.For setup instructions and the full list of available actions, refer to Browser Run Quick Actions.
AI Gateway now uses the AI REST API on
api.cloudflare.com. You can call any model — whether from OpenAI, Anthropic, Google, or hosted on Workers AI — through one unified API, using the same endpoints and authentication regardless of provider. Four endpoints are available:POST /ai/run— universal endpoint for all models and modalitiesPOST /ai/v1/chat/completions— OpenAI SDK compatiblePOST /ai/v1/responses— OpenAI Responses API compatiblePOST /ai/v1/messages— Anthropic SDK compatible
Terminal window curl -X POST "https://api.cloudflare.com/client/v4/accounts/$CLOUDFLARE_ACCOUNT_ID/ai/v1/chat/completions" \--header "Authorization: Bearer $CLOUDFLARE_API_TOKEN" \--header "Content-Type: application/json" \--data '{"model": "openai/gpt-5.5","messages": [{"role": "user", "content": "What is Cloudflare?"}]}'All AI Gateway features — logging, caching, rate limiting, and guardrails — are applied automatically. Third-party models are billed through Unified Billing, so you do not need to manage separate provider API keys.
Third-party model requests are routed through your account's default gateway, which is created automatically on first use. To route requests through a specific gateway, add the
cf-aig-gateway-idheader.If you are already calling Workers AI models through the existing REST API, that path (
/ai/run/@cf/{model}) continues to work. To call Workers AI models through AI Gateway, use the@cf/model prefix (for example,@cf/moonshotai/kimi-k2.6) and include thecf-aig-gateway-idheader to specify which gateway to route through.For more details and examples, refer to the REST API documentation.
The latest release of the Agents SDK ↗ brings more reliable chat recovery, fixes Agent state synchronization during reconnects, adds durable submissions for Think, exposes routing retry configuration, and adds connection control for Voice agents.
@cloudflare/ai-chatnow keeps server turns running when a browser or client stream is interrupted. This is useful for long-running AI responses where users refresh the page, close a tab, or temporarily lose connection. Callingstop()still cancels the server turn.Set
cancelOnClientAbort: trueif browser or client aborts should also cancel the server turn:JavaScript const chat = useAgentChat({agent: "assistant",name: "user-123",cancelOnClientAbort: true,});TypeScript const chat = useAgentChat({agent: "assistant",name: "user-123",cancelOnClientAbort: true,});Notable bug fixes:
- Chat stream resume negotiation no longer throws when replay races with a closed WebSocket connection.
- Recovered chat continuations no longer leave
useAgentChatstuck in a streaming state when the original socket disconnects before a terminal response. - Approval auto-continuation preserves reasoning parts and persists continuation reasoning in the final message.
isServerStreamingnow resets correctly when a resumed stream moves from the fallback observer path to a transport-owned stream.
agents@0.12.4prevents duplicate initial state frames during WebSocket connection setup. This avoids stale initial state messages overwriting state updates already sent by the client.Agent recovery is also more reliable when tool calls span a Durable Object restart. Recovery now defers user finish hooks until after agent startup and isolates hook failures, so one failed hook does not block other recovered runs from finalizing.
getAgentByName()now supportsroutingRetryfor transient Durable Object routing failures:JavaScript import { getAgentByName } from "agents";const agent = await getAgentByName(env.AssistantAgent, "user-123", {routingRetry: {maxAttempts: 3,},});TypeScript import { getAgentByName } from "agents";const agent = await getAgentByName(env.AssistantAgent, "user-123", {routingRetry: {maxAttempts: 3,},});@cloudflare/thinknow supports durable programmatic submissions.submitMessages()provides durable acceptance, idempotent retries, status inspection, cancellation, and cleanup for server-driven turns that should continue after the caller returns.Think.chat()RPC turns now run inside chat recovery fibers and persist their stream chunks. Interrupted sub-agent turns can recover partial output instead of starting over.ChatOptions.toolshas been removed from the TypeScript API. Define durable tools on the child agent or use agent tools for orchestration. Runtimeoptions.toolsvalues passed by legacy callers are ignored with a warning.@cloudflare/thinkno longer appliespruneMessages({ toolCalls: "before-last-2-messages" })to model context by default. The previous default could strip client-side tool results from longer multi-turn flows.truncateOlderMessagesstill runs as before, so context cost remains bounded. Subclasses that relied on the old aggressive pruning can opt back in frombeforeTurn:JavaScript import { Think } from "@cloudflare/think";import { pruneMessages } from "ai";export class MyAgent extends Think {beforeTurn(ctx) {return {messages: pruneMessages({messages: ctx.messages,toolCalls: "before-last-2-messages",}),};}}TypeScript import { Think } from "@cloudflare/think";import { pruneMessages } from "ai";export class MyAgent extends Think<Env> {beforeTurn(ctx) {return {messages: pruneMessages({messages: ctx.messages,toolCalls: "before-last-2-messages",}),};}}@cloudflare/voiceadds anenabledoption touseVoiceAgent. React apps can now delay creating and connecting aVoiceClientuntil prerequisites such as capability tokens are ready.JavaScript const voice = useVoiceAgent({agent: "MyVoiceAgent",enabled: Boolean(token),});TypeScript const voice = useVoiceAgent({agent: "MyVoiceAgent",enabled: Boolean(token),});This release also fixes Workers AI speech-to-text session edge cases and
withVoicetext streaming from AI SDKtextStreamresponses.- Streamable HTTP routing — Server-to-client requests now route through the originating POST stream when no standalone SSE stream is available.
- Structured tool output — Tool output shapes are preserved when truncating older messages or oversized persisted rows.
- Non-chat Think tool steps — Think agent-tool children can complete without emitting assistant text and can return structured output through
getAgentToolOutput. - Sub-agent schedules — Stale sub-agent schedule rows are pruned when their owning facet registry entry no longer exists.
@cloudflare/codemode— Adds a browser-safe export with an iframe sandbox executor and resolves OpenAPI specs inside the sandbox to avoid Worker Loader RPC size limits.
To update to the latest version:
Terminal window npm i agents@latest @cloudflare/ai-chat@latest @cloudflare/think@latest @cloudflare/voice@latestRefer to the Agents API reference and Chat agents documentation for more information.
We are refreshing the Workers AI model catalog to make room for newer releases. Please update your apps to remove references to the models listed below before the deprecation date.
@cf/zai-org/glm-4.7-flash— fast multilingual model with multi-turn tool calling and coding capabilities.@cf/google/gemma-4-26b-a4b-it— efficient open model with vision and tool calling.@cf/moonshotai/kimi-k2.6— capable tool-calling and vision model for agentic workloads and coding.
For pricing, refer to the Workers AI pricing page.
We originally stated Kimi K2.5 would be deprecated on May 10, 2026, however we have extended the deprecation date to May 30, 2026. Requests will be automatically aliased to Kimi K2.6 on May 30, 2026, which has a higher price. Please review the
@cf/moonshotai/kimi-k2.6pricing and model capabilities prior to May 30, 2026 to ensure that the model suits your needs.@cf/moonshotai/kimi-k2.5-->@cf/moonshotai/kimi-k2.6@hf/meta-llama/meta-llama-3-8b-instruct@cf/meta/llama-3-8b-instruct@cf/meta/llama-3-8b-instruct-awq@cf/meta/llama-3.1-8b-instruct@cf/meta/llama-3.1-8b-instruct-awq@cf/meta/llama-3.1-70b-instruct@cf/meta/llama-2-7b-chat-int8@cf/meta/llama-2-7b-chat-fp16@cf/mistral/mistral-7b-instruct-v0.1@hf/mistral/mistral-7b-instruct-v0.2@hf/google/gemma-7b-it@cf/google/gemma-3-12b-it@hf/nousresearch/hermes-2-pro-mistral-7b@cf/microsoft/phi-2@cf/defog/sqlcoder-7b-2@cf/unum/uform-gen2-qwen-500m@cf/facebook/bart-large-cnn
The
-fastand-loravariants of models will remain active, including:@cf/meta/llama-3.3-70b-instruct-fp8-fast@cf/meta/llama-3.1-8b-instruct-fast@cf/google/gemma-7b-it-lora@cf/google/gemma-2b-it-lora@cf/mistral/mistral-7b-instruct-v0.2-lora@cf/meta-llama/llama-2-7b-chat-hf-lora
LoRA models may be deprecated in the future. We will be adding more LoRA capabilities to the catalog, and will communicate when new LoRA models come online to give users time to train new LoRAs before we deprecate old ones.
For the full list of available models, refer to the Workers AI model catalog.
@cf/moonshotai/kimi-k2.6is now available on Workers AI, in partnership with Moonshot AI for Day 0 support. Kimi K2.6 is a native multimodal agentic model from Moonshot AI that advances practical capabilities in long-horizon coding, coding-driven design, proactive autonomous execution, and swarm-based task orchestration.Built on a Mixture-of-Experts architecture with 1T total parameters and 32B active per token, Kimi K2.6 delivers frontier-scale intelligence with efficient inference. It scores competitively against GPT-5.4 and Claude Opus 4.6 on agentic and coding benchmarks, including BrowseComp (83.2), SWE-Bench Verified (80.2), and Terminal-Bench 2.0 (66.7).
- 262.1k token context window for retaining full conversation history, tool definitions, and codebases across long-running agent sessions
- Long-horizon coding with significant improvements on complex, end-to-end coding tasks across languages including Rust, Go, and Python
- Coding-driven design that transforms simple prompts and visual inputs into production-ready interfaces and full-stack workflows
- Agent swarm orchestration scaling horizontally to 300 sub-agents executing 4,000 coordinated steps for complex autonomous tasks
- Vision inputs for processing images alongside text
- Thinking mode with configurable reasoning depth
- Multi-turn tool calling for building agents that invoke tools across multiple conversation turns
If you are migrating from Kimi K2.5, note the following API changes:
- K2.6 uses
chat_template_kwargs.thinkingto control reasoning, replacingchat_template_kwargs.enable_thinking - K2.6 returns reasoning content in the
reasoningfield, replacingreasoning_content
Use Kimi K2.6 through the Workers AI binding (
env.AI.run()), the REST API at/ai/run, or the OpenAI-compatible endpoint at/v1/chat/completions. You can also use AI Gateway with any of these endpoints.For more information, refer to the Kimi K2.6 model page and pricing.
Cloudflare's network now supports redirecting verified AI training crawlers to canonical URLs when they request deprecated or duplicate pages. When enabled via AI Crawl Control > Quick Actions, AI training crawlers that request a page with a canonical tag pointing elsewhere receive a 301 redirect to the canonical version. Humans, search engine crawlers, and AI Search agents continue to see the original page normally.
This feature leverages your existing
<link rel="canonical">tags. No additional configuration required beyond enabling the toggle. Available on Pro, Business, and Enterprise plans at no additional cost.Refer to the Redirects for AI Training documentation for details.
AI Crawl Control now includes new tools to help you prepare your site for the agentic Internet—a web where AI agents are first-class citizens that discover and interact with content differently than human visitors.
The Metrics tab now includes a Content Format chart showing what content types AI systems request versus what your origin serves. Understanding these patterns helps you optimize content delivery for both human and agent consumption.
The Robots.txt tab has been renamed to Directives and now includes a link to check your site's Agent Readiness ↗ score.
Refer to our blog post on preparing for the agentic Internet ↗ for more on why these capabilities matter.
New AI Search instances created after today will work differently. New instances come with built-in storage and a vector index, so you can upload a file, have it indexed immediately, and search it right away.
Additionally new Workers Bindings are now available to use with AI Search. The new namespace binding lets you create and manage instances at runtime, and cross-instance search API lets you query across multiple instances in one call.
All new instances now comes with built-in storage which allows you to upload files directly to it using the Items API or the dashboard. No R2 buckets to set up, no external data sources to connect first.
TypeScript const instance = env.AI_SEARCH.get("my-instance");// upload and wait for indexing to completeconst item = await instance.items.uploadAndPoll("faq.md", content);// search immediately after indexingconst results = await instance.search({messages: [{ role: "user", content: "onboarding guide" }],});The new
ai_search_namespacesbinding replaces the previousenv.AI.autorag()API provided through theAIbinding. It gives your Worker access to all instances within a namespace and lets you create, update, and delete instances at runtime without redeploying.JSONC // wrangler.jsonc{"ai_search_namespaces": [{"binding": "AI_SEARCH","namespace": "default",},],}TypeScript // create an instance at runtimeconst instance = await env.AI_SEARCH.create({id: "my-instance",});For migration details, refer to Workers binding migration. For more on namespaces, refer to Namespaces.
Within the new AI Search binding, you now have access to a Search and Chat API on the namespace level. Pass an array of instance IDs and get one ranked list of results back.
TypeScript const results = await env.AI_SEARCH.search({messages: [{ role: "user", content: "What is Cloudflare?" }],ai_search_options: {instance_ids: ["product-docs", "customer-abc123"],},});Refer to Namespace-level search for details.
AI Search now supports hybrid search and relevance boosting, giving you more control over how results are found and ranked.
Hybrid search combines vector (semantic) search with BM25 keyword search in a single query. Vector search finds chunks with similar meaning, even when the exact words differ. Keyword search matches chunks that contain your query terms exactly. When you enable hybrid search, both run in parallel and the results are fused into a single ranked list.
You can configure the tokenizer (
porterfor natural language,trigramfor code), keyword match mode (andfor precision,orfor recall), and fusion method (rrformax) per instance:TypeScript const instance = await env.AI_SEARCH.create({id: "my-instance",index_method: { vector: true, keyword: true },fusion_method: "rrf",indexing_options: { keyword_tokenizer: "porter" },retrieval_options: { keyword_match_mode: "and" },});Refer to Search modes for an overview and Hybrid search for configuration details.
Relevance boosting lets you nudge search rankings based on document metadata. For example, you can prioritize recent documents by boosting on
timestamp, or surface high-priority content by boosting on a custom metadata field likepriority.Configure up to 3 boost fields per instance or override them per request:
TypeScript const results = await env.AI_SEARCH.get("my-instance").search({messages: [{ role: "user", content: "deployment guide" }],ai_search_options: {retrieval: {boost_by: [{ field: "timestamp", direction: "desc" },{ field: "priority", direction: "desc" },],},},});Refer to Relevance boosting for configuration details.
We are renaming Browser Rendering to Browser Run. The name Browser Rendering never fully captured what the product does. Browser Run lets you run full browser sessions on Cloudflare's global network, drive them with code or AI, record and replay sessions, crawl pages for content, debug in real time, and let humans intervene when your agent needs help.
Along with the rename, we have increased limits for Workers Paid plans and redesigned the Browser Run dashboard.
We have 4x-ed concurrency limits for Workers Paid plan users:
- Concurrent browsers per account: 30 → 120 per account
- New browser instances: 30 per minute → 1 per second
- REST API rate limits: recently increased from 3 to 10 requests per second
Rate limits across the limits page are now expressed in per-second terms, matching how they are enforced. No action is needed to benefit from the higher limits.
The redesigned dashboard ↗ now shows every request in a single Runs tab, not just browser sessions but also quick actions like screenshots, PDFs, markdown, and crawls. Filter by endpoint, view target URLs, status, and duration, and expand any row for more detail.
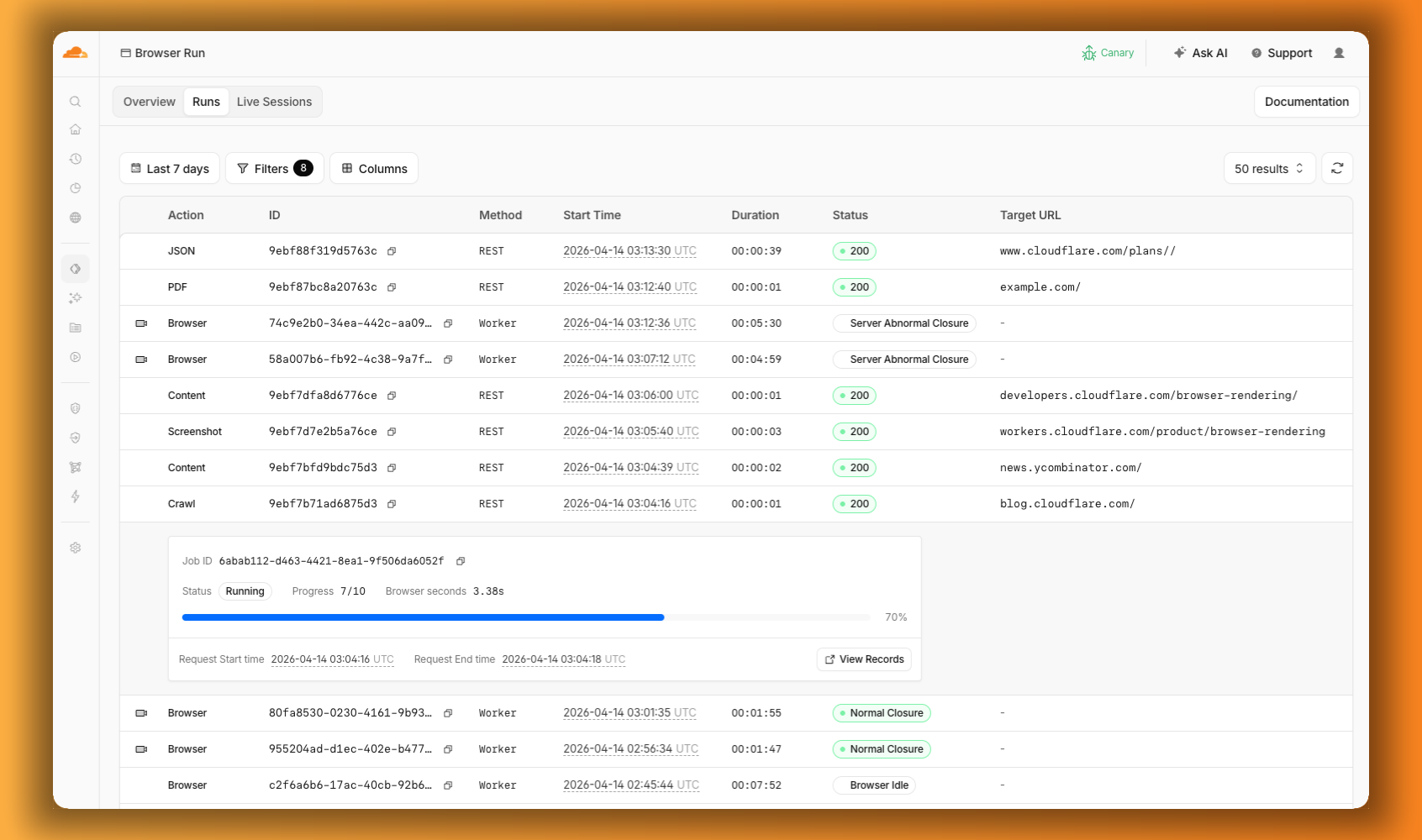
We are also shipping several new features:
- Live View, Human in the Loop, and Session Recordings - See what your agent is doing in real time, let humans step in when automation hits a wall, and replay any session after it ends.
- WebMCP - Websites can expose structured tools for AI agents to discover and call directly, replacing slow screenshot-analyze-click loops.
For the full story, read our Agents Week blog Browser Run: Give your agents a browser ↗.
When browser automation fails or behaves unexpectedly, it can be hard to understand what happened. We are shipping three new features in Browser Run (formerly Browser Rendering) to help:
- Live View for real-time visibility
- Human in the Loop for human intervention
- Session Recordings for replaying sessions after they end
Live View lets you see what your agent is doing in real time. The page, DOM, console, and network requests are all visible for any active browser session. Access Live View from the Cloudflare dashboard, via the hosted UI at
live.browser.run, or using native Chrome DevTools.When your agent hits a snag like a login page or unexpected edge case, it can hand off to a human instead of failing. With Human in the Loop, a human steps into the live browser session through Live View, resolves the issue, and hands control back to the script.
Today, you can step in by opening the Live View URL for any active session. Next, we are adding a handoff flow where the agent can signal that it needs help, notify a human to step in, then hand control back to the agent once the issue is resolved.
Session Recordings records DOM state so you can replay any session after it ends. Enable recordings by passing
recording: truewhen launching a browser. After the session closes, view the recording in the Cloudflare dashboard under Browser Run > Runs, or retrieve via API using the session ID. Next, we are adding the ability to inspect DOM state and console output at any point during the recording.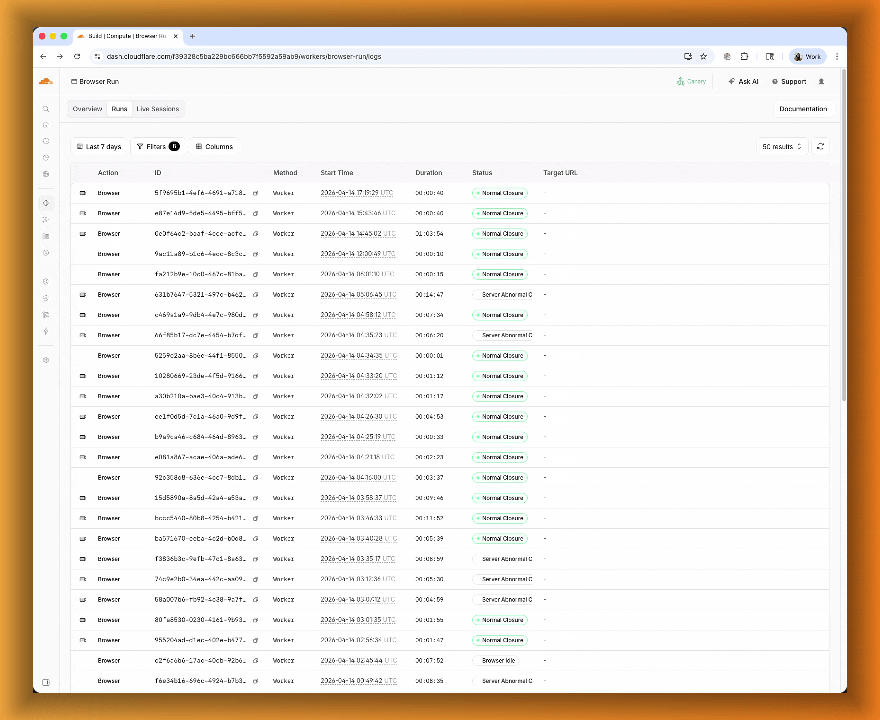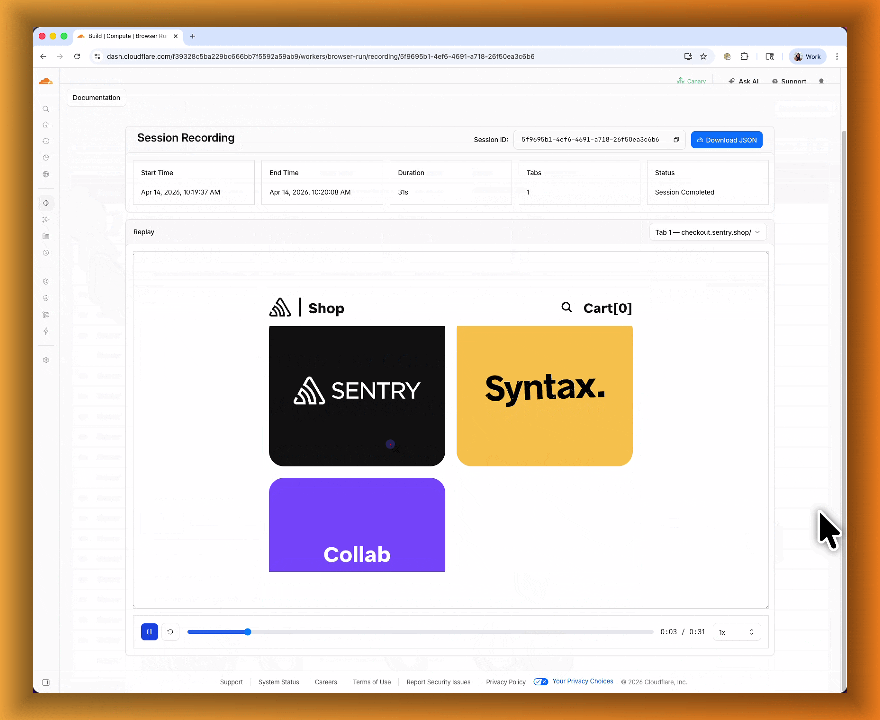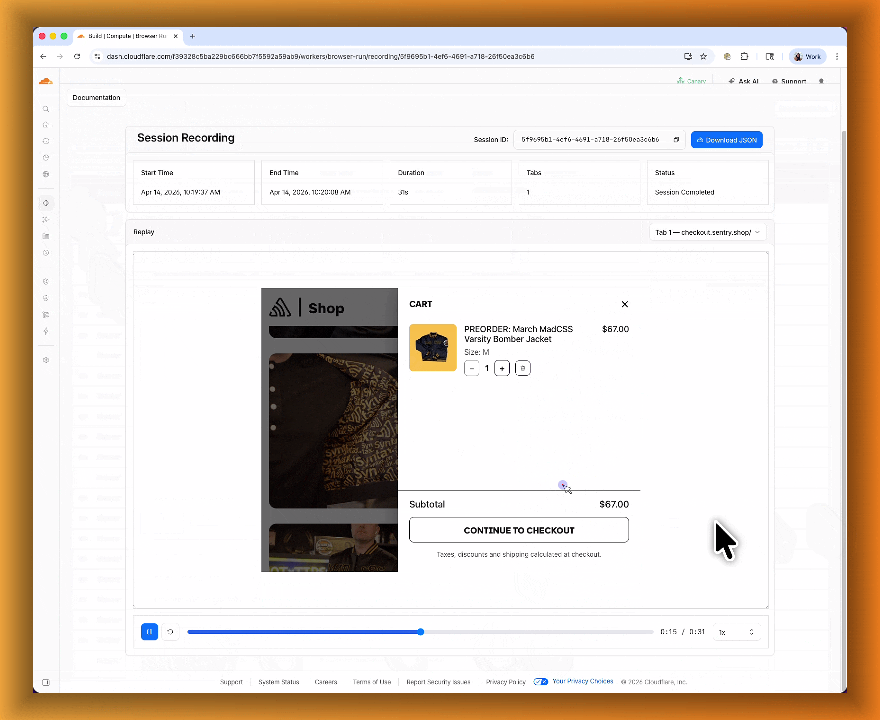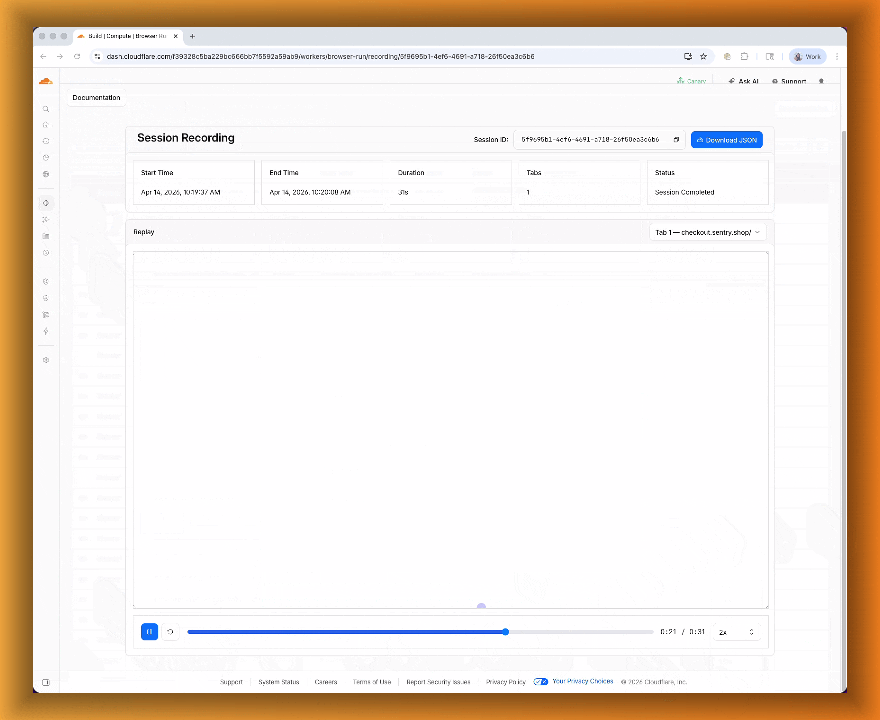
To get started, refer to the documentation for Live View, Human in the Loop, and Session Recording.
Browser Run (formerly Browser Rendering) now supports WebMCP ↗ (Web Model Context Protocol), a new browser API from the Google Chrome team.
The Internet was built for humans, so navigating as an AI agent today is unreliable. WebMCP lets websites expose structured tools for AI agents to discover and call directly. Instead of slow screenshot-analyze-click loops, agents can call website functions like
searchFlights()orbookTicket()with typed parameters, making browser automation faster, more reliable, and less fragile.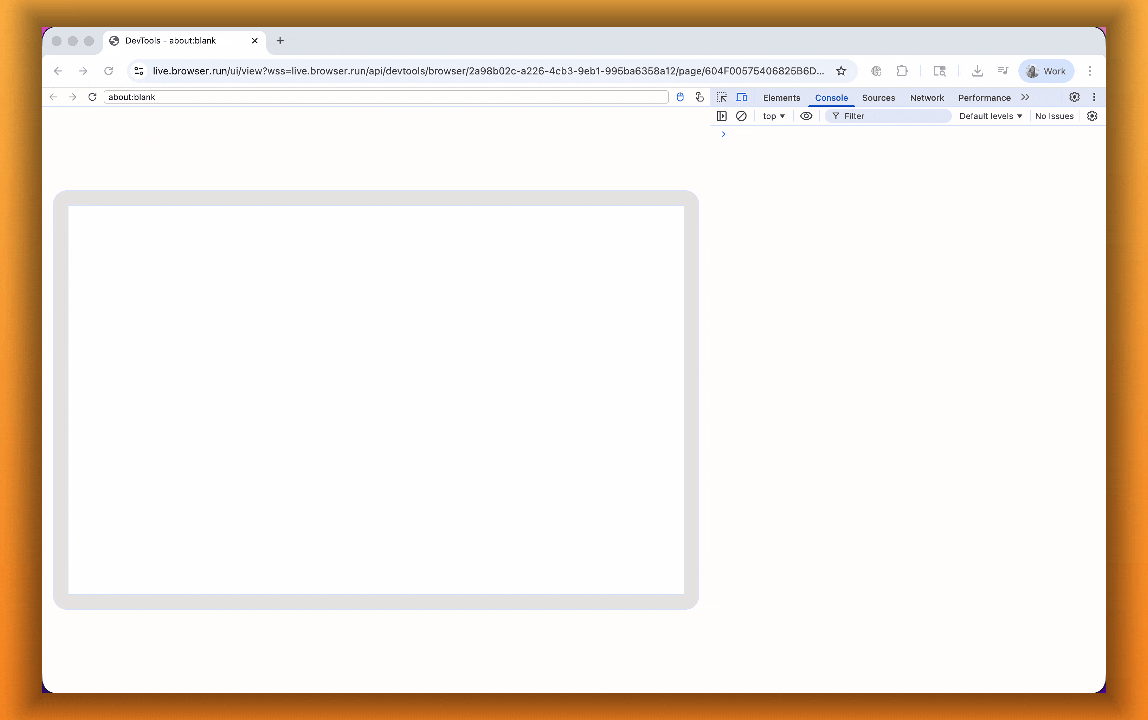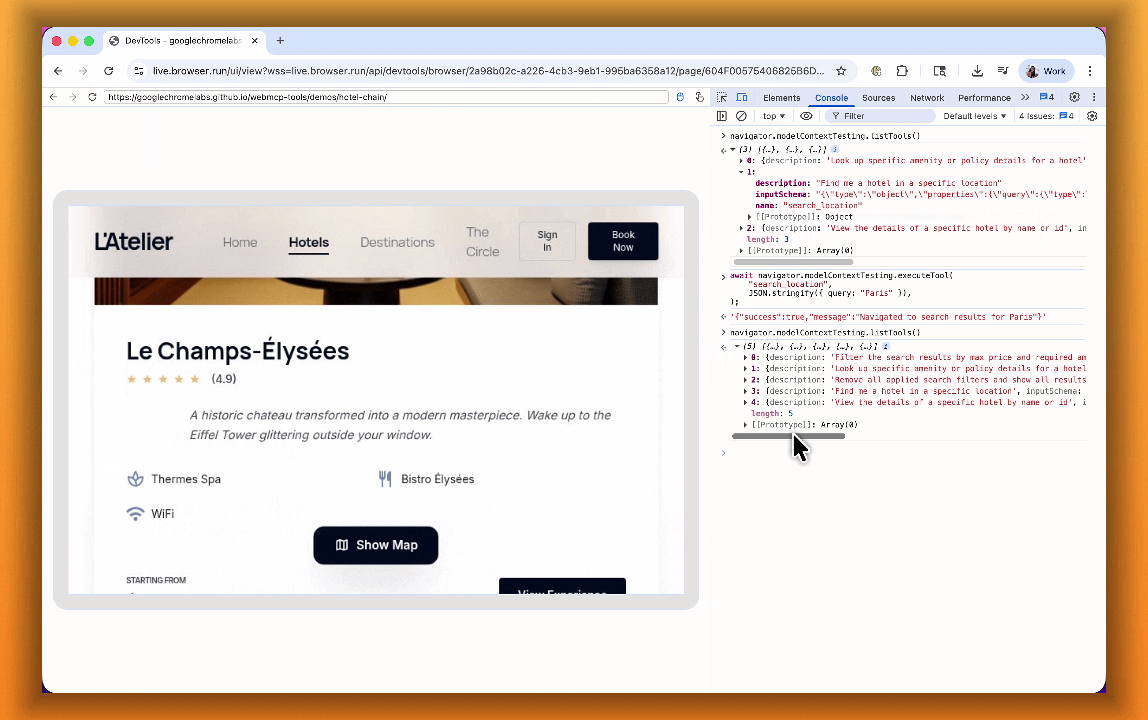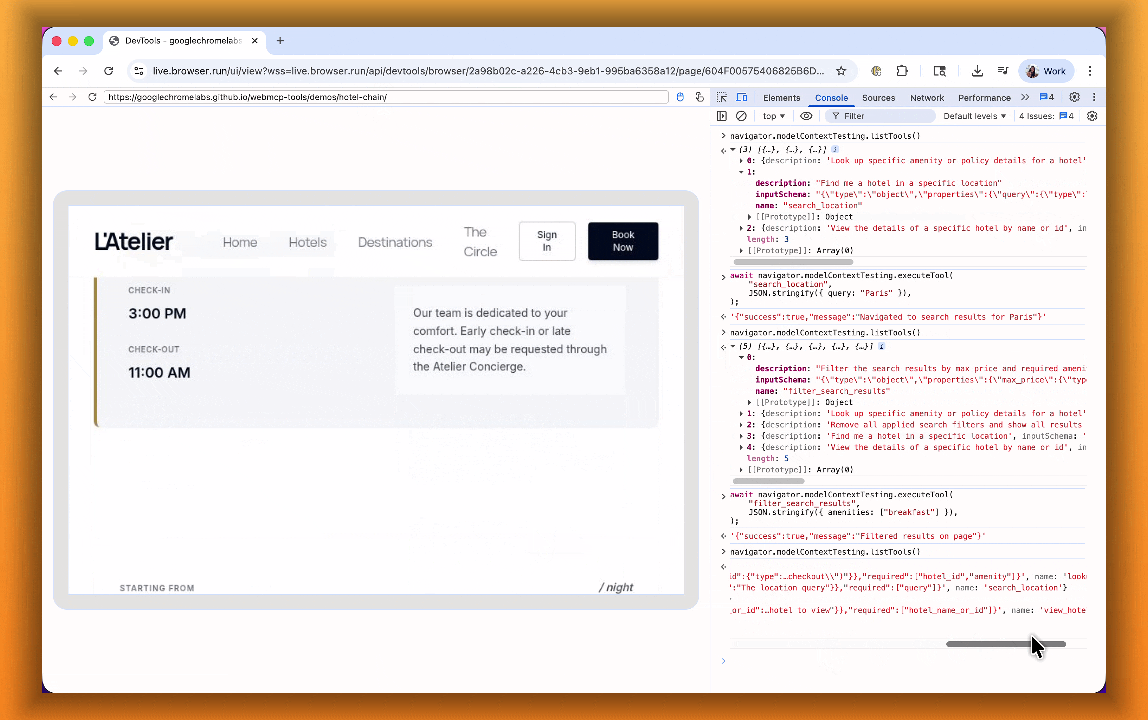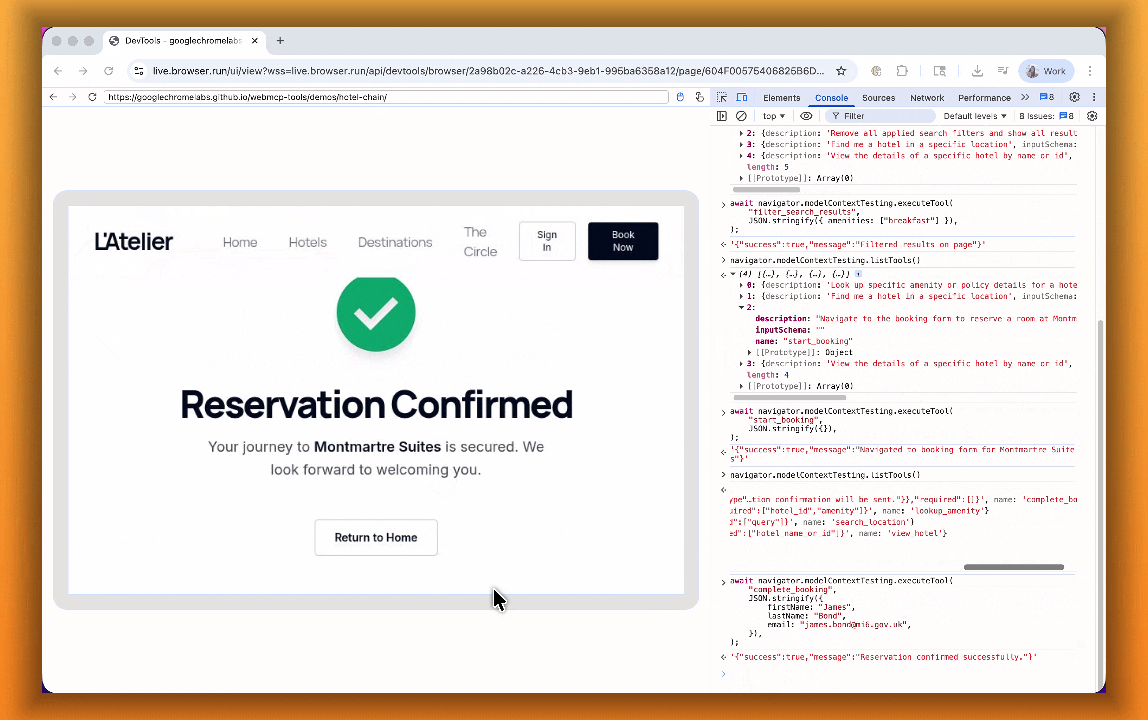
With WebMCP, you can:
- Discover website tools - Use
navigator.modelContextTesting.listTools()to see available actions on any WebMCP-enabled site - Execute tools directly - Call
navigator.modelContextTesting.executeTool()with typed parameters - Handle human-in-the-loop interactions - Some tools pause for user confirmation before completing sensitive actions
WebMCP requires Chrome beta features. We have an experimental pool with browser instances running Chrome beta so you can test emerging browser features before they reach stable Chrome. To start a WebMCP session, add
lab=trueto your/devtools/browserrequest:Terminal window curl -X POST "https://api.cloudflare.com/client/v4/accounts/{account_id}/browser-rendering/devtools/browser?lab=true&keep_alive=300000" \-H "Authorization: Bearer {api_token}"Combined with the recently launched CDP endpoint, AI agents can also use WebMCP. Connect an MCP client to Browser Run via CDP, and your agent can discover and call website tools directly. Here's the same hotel booking demo, this time driven by an AI agent through OpenCode:
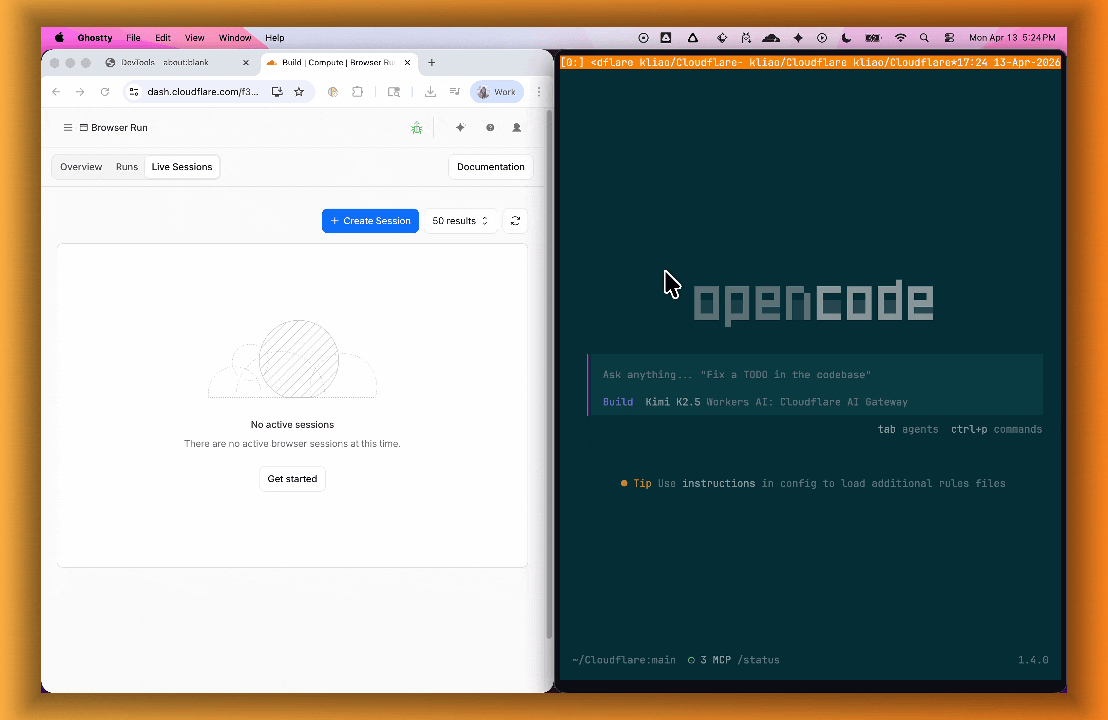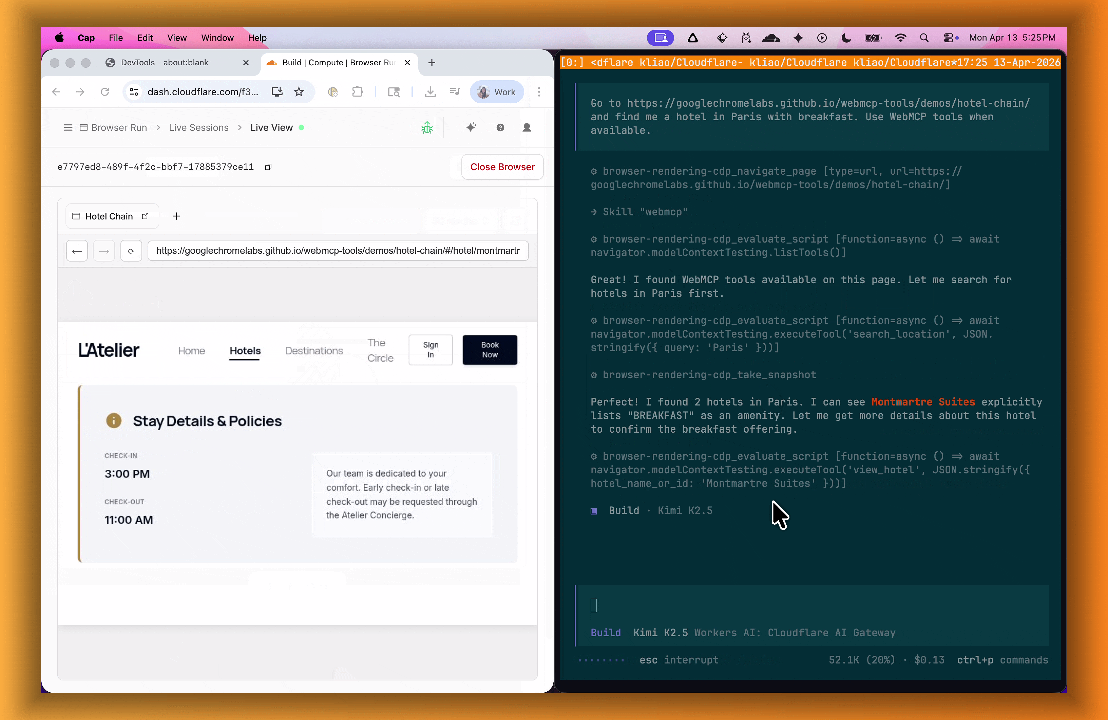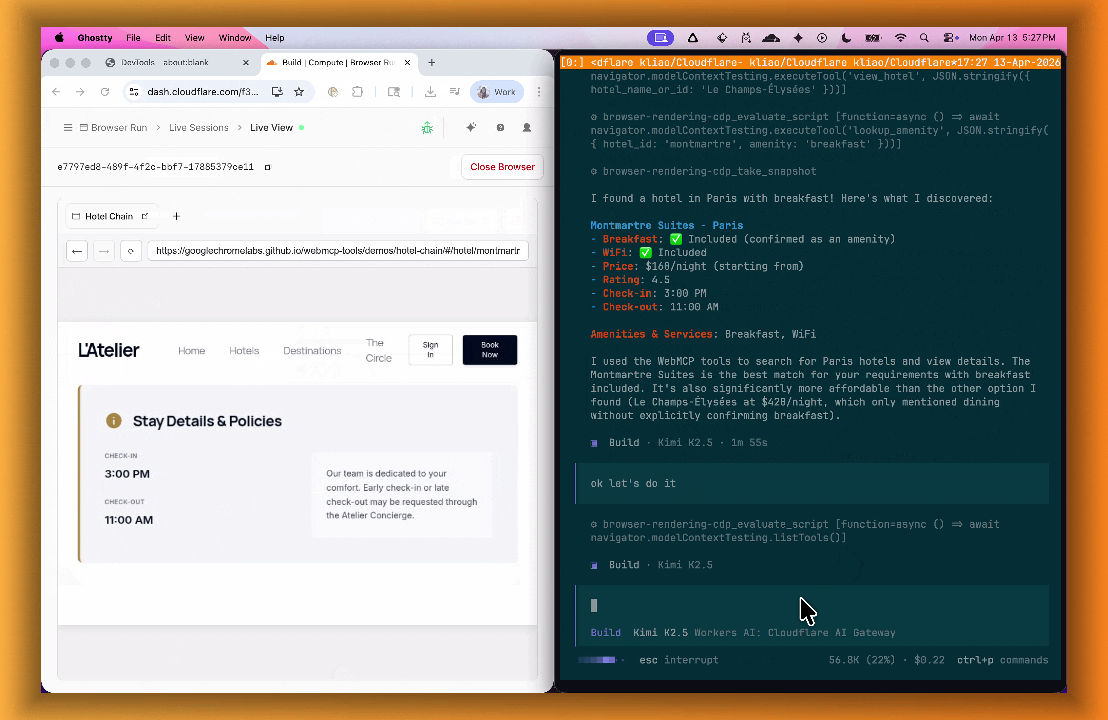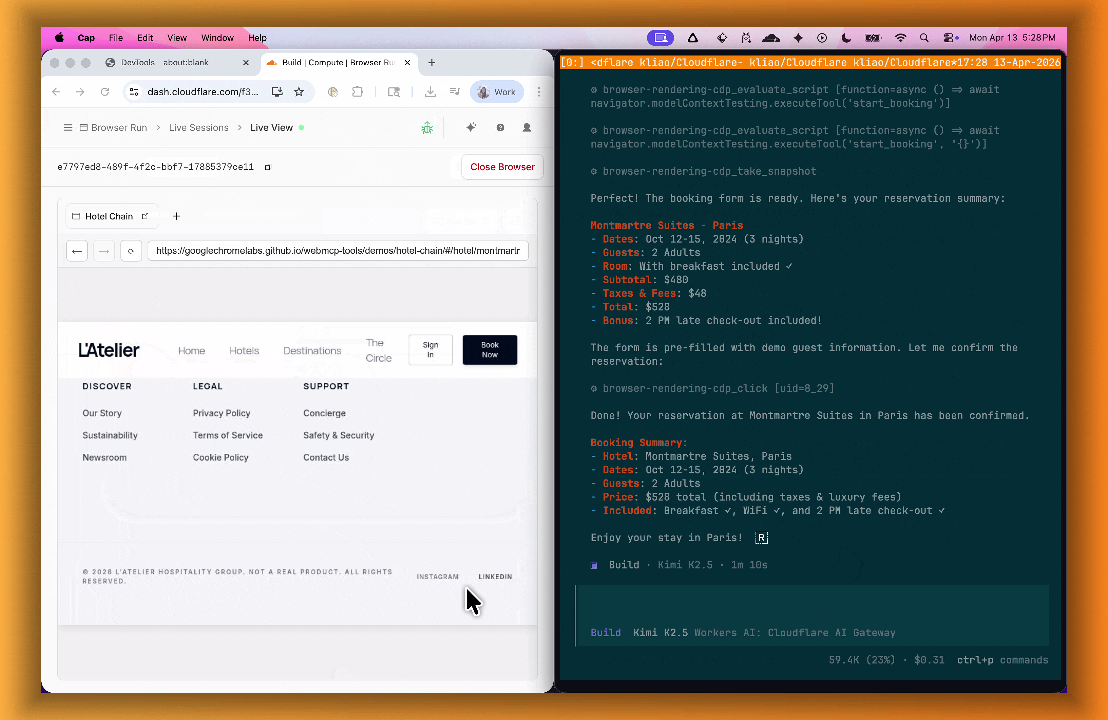
For a step-by-step guide, refer to the WebMCP documentation.
- Discover website tools - Use